EXIとは何か? (準備編)
http://live-e.naist.jp/sensor_overlay/6/でEXIの話をして、「日本語のEXIの解説記事がない」ということに今さらながら気がつきました。WikipediaのEXIのエントリでも良いのですが、百科事典は解説ではないのと、僕の解釈は偏っているので、こちらに書こうと思います。今日はまだ準備編です。
英文の解説が以下のURLで読めます。
本解説は、EXI Primerの概要紹介と、特に私が注力している、Schema-Informed Grammar の説明をさせて頂きます。なお、以下簡単のために意図的に単純化して書いている場合があります。例えば、Document Fragmentの 扱いなどについては書いていません。
シリーズとしては以下のように考えていますが、必要に応じて順番や内容は変更の可能性があります。
- EXIの概要 (EXI Primer Primer) ← 今日はこれ。
- [EXI][技術] データ型とその符号化 - doiの連絡帳
- EXIにおける文字列 (String) と QName - doiの連絡帳
- Schema-Informed Grammarと状態機械
- ポリモーフィズムの実現: xsi:any と String Table
- EXI by Example を読み解く
準備
EXIでは、符号長がバイト単位ではなくビット単位です。以下、このシリーズではpビットで表現された値vを、v"_"p"b"で表現します。vは特に指定のないかぎり10進数です。また、短い符号については、"0b"xxxx と、0bのプレフィックスで2進数表記します。
例:
- 0b0 = 0_1b
- 0b010 = 2_3b
- 0b10110 = 22_5b
- (対応表現なし) = 0_0b
最後の例は、符号長0のケースで、EXIにおいてはしばしば利用されます。表現すべき値域の幅が1のとき、情報量としてはゼロになることに由来します。
EXI Primer Primer
Efficient XML Interchange (EXI) Primer は、以下の構成となっています (セクションタイトルは意訳しています)。
- 導入
- コンセプト
- EXIストリームの構成
- EXIヘッダ
- EXI本文
- EXI文法 (組み込み文法、スキーマ由来文法)
- コンテンツの表現
- 組み込みEXIデータ型
- 文字列表
- 圧縮との併用
- EXIストリームの構成
- 例で学ぶEXI
以下、順を追って簡単に説明します。
EXIとは何なのか
EXIは、XMLの冗長性を極力排し、バイナリで記述することによりコンパクトに表現する「表現形式」です。しばしばEXIを表現するときに「XMLの圧縮」という言い方をしますし、その側面があることも否定しませんが、本質的には「代替の直列化フォーマット」と言ったほうが理解しやすいと思います。普段見るXMLは、XMLが本来持つデータモデル*1を文字列*2で符号化したものです。
EXIの設計原則 は、以下の5つです。
- 汎用: 特定の用途に向けたものではなく、XMLが利用できるあらゆる場面で利用できるようにすること
- 最小: 組込機器も含めたさまざまな環境に適用可能とするために、小さく洗練な手法であること
- 効率: EXIは、特定用途向けにカスタマイズされたバイナリデータ形式と同程度に効率的であること
- 柔軟: EXIは多様なスキーマやその拡張、またスキーマからの逸脱を許容できること
- 相互運用可能: EXIは既存のXML情報モデル (XML Information Set (Second Edition)) と互換で、既存のXML標準を利用する際に必要な工夫を最小とすること
XMLを効率的に表現するために、XMLの文字列表現を捨て、構造を直接記述しています。XMLプログラミングになじみのある方であれば、DOMではなくSAXやStAXで利用される「イベント」を直列化している、と考えると理解しやすいと思います。
EXIストリームはどんな構造をしているか
EXI Primer の 2.1.1, 2.1.2 の説明です。
Efficient XML Interchange (EXI) Primer Table 2-1 を見ると、EXIストリームはヘッダとボディの2つから構成されることがわかります。ヘッダは、Table 2-2に示されていますが、以下の要素からなります。
- EXI Cookie
- このストリームがEXIであることを示す文字列。"$EXI"(4バイト)で固定。あってもなくてもよい。
- Distinguishing Bits
- 仮にEXI Cookieがなかったとしても、このストリームがXML (あるいはUTF-8) ではなくEXIであることを示すためのビット。2ビットで、値は0b10で固定。
- Presence Bit for EXI Options
- EXIオプション (後述) が存在するかどうかを示すビット。1ビットで、1のときにEXIオプションがヘッダの直後に追加されます。
- EXI Format Version
- EXIのバージョンで、現在はバージョン1で、 0b00000 (5ビット) となります。
- EXI Option
- 符号化のオプションを詳細に記述することができます。オプション自体を省略した場合は、アプリケーション固有の別の方法(決め打ちなども含む)でオプションが指示されているものとします。EXI Option自体もまたEXIで符号化されているXMLですが、EXI Optionを符号化するためのオプションは固定されています。
EXIの符号化オプションは Table 2-3, 2-4 に示されていますが、詳細は別途述べます。
XMLの本文は、EXIボディに符号化されます。Efficient XML Interchange (EXI) Primer に内容が書いてありますが、大切なのは Figure 2-1です。大切な図なので以下に引用してみます。
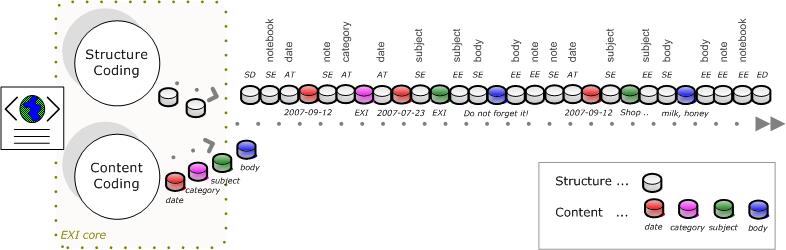
(EXI Primerより引用)
図の左側にあるのがXMLです。頭を抱えている人ではありません。XMLは、「Structure(構造)」と「Content(内容)」にわかれます。例えばXML要素を区切るためのタグは構造の符号化で、タグ(<と>)の外のテキスト、要素の値などは内容です。図中、データの単位が小さな円柱で表現されています。うち、色がつけられているものが内容に対応する「イベント」で、白いものが構造に対応する符号です。構造を表現するイベントの種別は、図のちょっと上にある Table 2-5 にまとめられています。大切なのは以下の5つです。
- SD(Start Document)
- 文書の開始を示すイベント種別
- ED(End Document)
- 文書の終了を示すイベント種別
- SE(Start Element)
- 要素の開始を示すイベント種別で、通常は開始タグに対応 (例: <a> → SE(a))
- EE(End Element)
- 要素の終了を示すイベント種別で、通常は終了タグに対応 (例: </a> → EE)
- AT(Attribute)
- 属性の存在を示すイベント種別で、通常はSEの直後に存在 (例: <a b="c"> → SE(a)AT(b)"c")
Figure 2-1 を見ると、以下のようにイベントが並んでいます。また、Figure 2-1 の中ではEEイベントにもタグ名が記載されていますが、実際のEXIストリームにおいてはEEイベントにはタグ名に対応する情報を含まないため、省略しています。
SD
SE(notebook)
AT(date) "2007-09-12" SE(note)
AT(category) "EXI" AT(date) "2007-07-23" SE(subject)
"EXI" EE
SE(body)
"do not forget it!" EE
EE
SE(note)
AT(date) "2007-09-12" SE(subject)
"Shop.." EE
SE(body)
"milk, honey" EE
EE
EE
ED整形すると、なんとなくXMLに見えてくると思います。インデントは、SEで1段増やし、EEで1段減らす、というルールで書いています。インデントの段がSEとEEでずれているのに注意してください。例えば
<body>milk, honey</body>
は
SE(body) "milk, honey" EE
となっています。この「ずれ」にはEXIの符号化に関する思いが込められています。詳細な説明は「Schema-Informed Grammarと状態機械」で行う予定ですが、簡単に言うと、イベントは実際には (イベント種別,パラメータ,値) の組になっています。上の例ですと、body要素を表現するイベントは (SE, body, SE要素の値) の3つ組になります。ここで言う「SE要素の値」が、(CH*3,(空),"milk, honey"), (EE,(空),(空)) という2つのイベントになります。
オートマトン用語で言うと、SE(body)で現在の状態をスタックに積んだ上で、bodyの型に対応する新しい状態機械(子状態機械とでも呼びましょうか)を作って開始します。この子状態機械はEEまでのストリームを受け取り、EEで子状態機械を終了させます。子状態機械が終了した結果、スタックがポップされ、親にあたる状態機械が継続します。
EXIの文法と文書構造の符号化
(EXI Primer の 2.1.3の説明です -- とはいえ、いきなりコード割当の説明とか無理なので、説明のやりかたは変えます)
EXIは、文法により文書構造の符号化を行います。EXIの文法には2種類あります。Built-in Grammar と Schema-Informed Gramar の2種類です。書いてて長いので、それぞれ、組み込み文法、スキーマ由来文法と呼ぶこととします*4。組み込み文法は僕もちゃんと理解できていないので、ざっくりとした書きかたになってしまうことをご容赦ください。
EXIの文法は、エンコーダとデコーダとの間で共有されている、同期した一組の状態機械です。組み込み文法は、エンコーダにおいてはXML文書の入力、デコーダにおいてはEXIストリームの入力に対応して変化します。この学習により、スキーマの存在しないXML文書、あるいはスキーマから逸脱したXML文書の逸脱部分について、潜在的な構造を効率的に学習し転送することができるようになります。また、スキーマ由来文法はスキーマを持つXML文書の符号化に適した文法で、スキーマ由来文法自体はスキーマから生成されることから、入力となるXML文書の内容によらず変化しません。
EXIの文法の状態機械において、状態遷移には前述のEXIのイベントが割り当てられます。イベント種別とパラメータ条件*5の組み合わせに対し、確定的に1つの遷移が定義されます。Figure 2-2が組み込み文法の例、Figure 2-3がスキーマ由来文法の例です。図示された文法は実際のEXI文法の断片に過ぎず、EXI文法は総体として、文書文法 (Document Grammar) および、型の数だけ個別に定義される型文法 (Type Grammar) の組み合わせ*6から成ります。
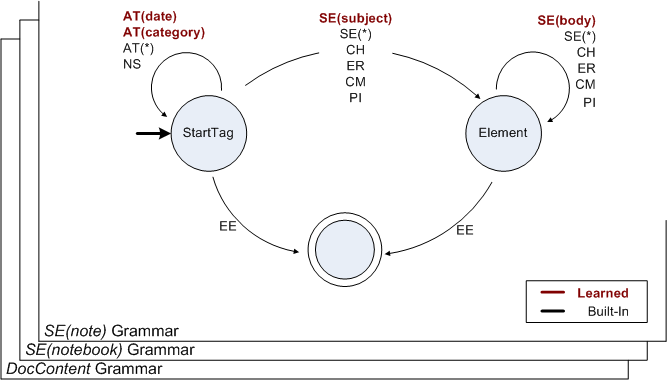{kind=link}
このように定義した文法を、エンコーダとデコーダで共有し、エンコード・デコードに際して同期して動作させます。文法の状態遷移には、全てにイベントコードが振られ、これを符号として利用します。エンコーダは、XML文書を入力として、これを一つ前のセクションで説明したような、イベントの列 (SD, SE, EE, ...) に変換します。イベントを先頭から順番に取り出し、状態機械の現在状態から、対応するイベントに合致する遷移を選択し、符号化します。一方デコーダは、受信したEXIストリームから符号を一つ取り出し、状態機械の現在状態から符号に合致する遷移を選択し、この遷移に対応付けられたイベントをデコードします。
静的な分説明が簡単なので、本稿ではまず、スキーマ由来文法を例に説明します。Figure 2-3を以下に引用します。
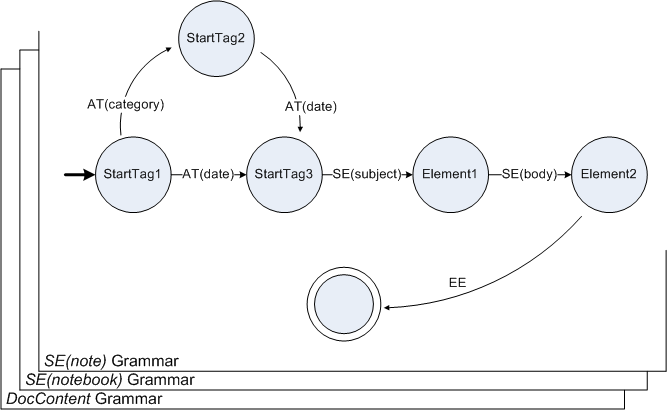
(EXI Primer Figure 2-3より引用)
これは、あるXMLスキーマ (Example 2-2) から生成されたスキーマ由来文法のうち、note要素に対応する型文法です。どのように生成されるかについては、ここでは説明しません。シリーズ中の、「Schema-Informed Grammarと状態機械」で説明予定です。よく見ると状態機械自体がスタック状になっていて、現在は文書文法 (DocContent Grammar) の上で notebook要素に対応する文法が動作しており、その値に含まれるイベント列のうち、SE(note)によりnote要素に対応する文法がさらに生成されています。以下、まずイベント番号を使わずに説明した後、どのようにイベントをビット列に符号化するかについて述べます。なお、実際には Figure 2-1 の Content Encoding に対応する部分、つまり、個々の属性の値や、他の文字列 (地の文) についても符号化方式がいろいろあります。概略については次の節で述べますが、詳細は「データ型とその符号化」にて説明します。
note要素が以下のようになっていたとします。
<note category="EXI" date="2007-07-23"> <subject>EXI</subject> <body>do not forget it!</body> </note>
このXMLは、以下のEXIイベント列に対応します。行番号は説明のために入れたものです。
1: SE(note) 2: AT(category) "EXI" AT(date) "2007-07-23" SE(subject) 3: "EXI" EE 4: SE(body) 5: "do not forget it!" EE 6: EE
ここで、二段目のインデント以下は、note型ではなくその次の状態機械で符号化されます。説明を簡単にするために、まずはSE(note)に対応する状態機械だけで考えるので、3行目と5行目は隠します。別の言い方をすると、3行目は、2行目の SE(subject)に対応する値で、5行目は4行目のSE(body)に対応する値になります。また、2行目のATに対応する値も、同様に構造の符号化には無関係なので省略します。
1: SE(note) 2: AT(category) AT(date) SE(subject) 4: SE(body) 6: EE
最初のSE(note)により、Figure 2-3 の文法が開始されます。StartTag1とラベル付けされた状態になります*7。2行目のイベントの最初を取ると、AT(category) です。値も含めた解釈を行い、StartTag2の状態に遷移します。次のイベントは、AT(date)ですので、StartTag3に移動し、次のSE(subject)でElement1の状態に遷移します。SE(body)でElement2に遷移し、EEにより終了状態 (二重丸) に遷移します。EEに遷移したところでこのnote要素に対応する文法は破棄され、一つ下に存在するnotebook要素の状態機械が再開されます。
このように、イベントと状態遷移は一つひとつ対応が取られています。ここで、状態遷移に番号 (イベントコード) が付与されていることから、この番号を順次符号として利用すれば良いことになります。イベントコードは0ではじまるので、今回のイベントコードは (0,0,0,0,0) となります。例えば、category属性が省略された場合は、最初の遷移が AT(date) になりますので、(1,0,0,0) となります。
ところで、この状態遷移機械の持つ情報量はどれぐらいでしょうか?*8 仮にひとつのイベントコードを1バイトで符号化したとしても4〜5バイト (32〜40ビット) になりますが、どう見てもこの状態遷移機械にそれだけのエントロピーがあるようには見えません。そこで、EXIのデフォルトのモードでは、このような疎なイベントコードを効率的に符号化するために、値域を表現するのに必要十分なビット幅で数値を符号化する、n-bit unsigned integerという符号化方式が取られます(EXI Format 1.0 Section 7.1.9)。ここで、note要素に対応する状態機械は、StartTag1のみ遷移数(out-edge)が2、その他は1です。遷移数が1ということは、情報量としてはゼロなので、ゼロビット幅の符号で表現できます。
以上から、実際のイベントコードは (0_1b, 0_0b, 0_0b, 0_0b, 0_0b) つまり 0b1 または (1_1b, 0_0b, 0_0b, 0_0b) つまり 0b0 になります。なんと状態遷移が1ビットで表現できました*9。デフォルトでは、EXIの符号はバイト境界などを無視して、ビット単位で詰め込まれます。例えば、このnote要素が100個あったら、note要素の構造を表現するのに100ビット = 12.5バイトしか使わない、と言うこともできます。実際には、個々の値の符号化や、notebook要素における状態遷移が間に挟まるのでもっと長くなります。
最後に、組み込み文法について簡単に説明します。
組み込み文法は、XMLの文書あるいはその要素断片などを学習して、状態遷移を増やします。具体的には、デフォルト遷移 (AT(*)とかSE(*)とか、他にマッチする条件がなければマッチする遷移) が定義されていて、その遷移の副作用として遷移を増やします。当然、最初の遷移では、要素名や属性名の情報を文法の状態として持っていませんので、符号に付随したパラメータに、文字列の形で記述する必要があります。これをエンコードする文法は、エンコードした際に利用している組み込み文法に、対応する遷移を追加します。デコードする文法も同様に、最初は文字列による要素名・属性名を受け取りますが、同時に組み込み文法の状態機械に、当該要素名・属性名に対応する遷移を追加します。二度目以降の同名要素・属性は、エンコード時には先だって追加した遷移を利用することで符号化できます。デコード時は、追加した遷移に対応する符号を受け取ることで、その遷移に対応するイベントを取り出すことができます。
別の言いかたをすると、組み込み文法は、最初に登場した要素名や属性名について、最初だけ文字列を符号化しますが、2度目は例えば「さっき使った2番目の奴」というような示し方をします。
EXIにおけるデータ表現
(EXI Primer の 2.2の概略です)
EXIにおけるデータ表現もいろいろとややこしいのですが、基本的には以下の3つが特徴です。
- スキーマにより型が確定しており、かつその型定義に従う値については、バイナリにより効率的に符号化される (EXI Format 1.0 Section 7.1)
- 列挙型は、その列挙型を表現するのに必要十分な n-bit unsigned integer で符号化される (EXI Format 1.0 Section 7.2)
- 文字列は、文字列表 (String Table) により管理され、複数回登場する文字列、あるいは初期化時に定義される文字列については n-bit unsigned integer により符号化される (EXI Format 1.0 Section 7.3)
詳細は、「データ型とその符号化」で書く予定です。
EXIと圧縮の関係
(EXI Primer の 2.3の概略です)
EXIの圧縮は使っていないので概略しか把握していませんが、EXIの符号に、さらにエントロピベースの圧縮をかけることが可能です。このとき、DEFLATEと呼ばれる標準的なアルゴリズムを利用します。この圧縮の効率を上げるために、EXIの符号の順序を入れ替え、似たような表現が近くになるようにします(Figure 2-8)。
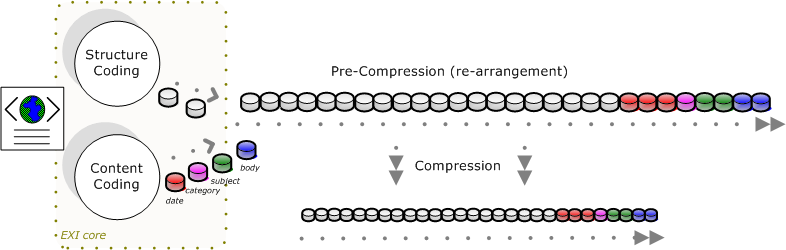{kind=link}
EXIの具体例
EXI Primerの section 3 にEXIの具体例が書いてありますが、実際にはこの内容をちゃんと理解しようと思うとEXI Primerに書かれている知識だけでは足りません。ですので、この項目の解説は最後にやろうと思います。
付録
以下付録です。
用語集
- Grammar
- あるXMLスキーマまたはXML文書により定義される文法の集合 (一つのDocument Grammarおよび一組のType Grammar であり、プッシュダウンオートマトンを構成する)
- Document Grammar
- 文書のRoot要素を決定する文法
- Type Grammar
- XMLスキーマで定義される「型」を定義する文法 (一つの型に対して、一つの状態機械)
- Built-in Grammar
- 文法の作成方法のひとつで、未知のイベント(オートマトン的に言うと「単語」)に対する遷移と、新しい単語の学習との組み合わせ。新しく登場した要素については、新しく文法を作成する。要素や属性が新規に登場した場合は随時文法(状態機械)自体が増えていく。
- Schema Informed Grammar
- 文法の作成方法のひとつで、XMLスキーマを入力として、スキーマに定義される型や要素について、静的な状態機械を生成する。なお、Schema Informed Grammar には strict と non-strict の2つのモードがあり、strict ではXMLスキーマに対して妥当な(状態機械がacceptできる)XMLのみを受け付け、non-strict ではXMLスキーマに対して妥当でない要素や属性が存在する場合に、これを Built-in Grammar で処理する。
試訳 (案)
頻出語については以下の訳語を使っています。この訳語はあくまでも土井の試訳ですので、あいまいさのない状況で利用したい場合は英単語を使ってください。
- Grammar
- 文法
- Built-in Grammar
- 組み込み文法
- Schema Informed Grammar
- スキーマ由来文法
- Document Grammar
- 文書文法
- Type Grammar
- 型文法
- String Table
- 文字列表
- Element
- 要素
- Attribute
- 属性
ChangeLog
- 2013-06-08: EXI wg chairの上谷様より頂いたコメントにもとづき修正
*1:Document Object Model (DOM) で表現できるもの
*3:Characters、つまり文字列を示すイベント種別です
*4:日本語って便利ですね!
*5:パラメータ条件は、例えば、特定の要素名(SE(ns0:foo)など)、あるいは特定の名前空間の任意の要素名(SE(ns0:*)など)、任意の要素名(SE(*)など)といったものであり、より特定的な指定が優先されます。
*6:個人的には、文字列表の初期化ベクトルも文法の一部と捉えています。土井、佐藤 「XMPPの効率的なEXI符号化を実現する動的文法合成方式」 情処IOT研究会研究報告 2013年5月 参照。
*7:ちなみに、状態に付与されたラベルには説明用以外の意味はありません。
*8:遷移のパターンが2通りしかないから、1ビットですよね。
*9:今回は遷移が2通りしかないため、どの遷移をしても符号長が1ビットになりますが、実際には遷移によって符号長は異なる場合があります。